Meet Swin3D++: An Enhanced AI Architecture for Efficient Pretraining on Multi-Source 3D Point Clouds
In the field of 3D understanding, point clouds serve as a prevalent representation of 3D data. Extracting point-wise features is crucial for various tasks related to 3D understanding, such as semantic segmentation, detection, and instance segmentation. Deep learning methods have made significant strides in this domain, but they often face challenges due to the scarcity and limited annotation of 3D data. To overcome these challenges, researchers have proposed an enhanced AI architecture called Swin3D++.
The Challenges of 3D Pretraining
One of the main challenges in 3D pretraining is the scarcity of labeled 3D data. Unlike natural language processing and 2D vision, where large and diverse datasets are readily available, 3D datasets are limited and often require manual annotation. This scarcity hinders the development and impact of 3D pretraining methods.
To address the data scarcity issue, one straightforward solution is to merge multiple existing 3D datasets and employ the combined data for universal 3D backbone pretraining. However, this approach overlooks the domain differences among different 3D point clouds. These differences, such as variations in point densities, signals, and noise characteristics, can adversely affect pretraining quality and performance.
Introducing Swin3D++
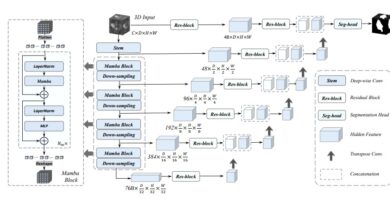
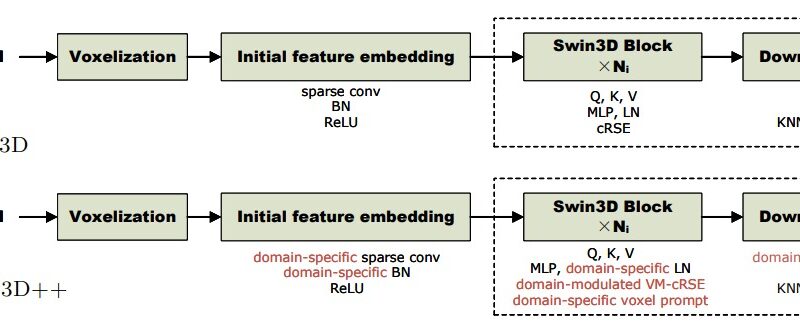
To tackle the domain discrepancy problem in multi-source pretraining, researchers have proposed an enhanced AI architecture called Swin3D++. Swin3D++ extends the Swin3D framework and incorporates domain-specific mechanisms to handle the variations in different 3D point clouds.
The main contributions of Swin3D++ include the following:
- Domain-Specific Voxel Prompts: Swin3D++ introduces domain-specific voxel prompts to handle sparse and uneven voxel distribution across domains. This mechanism helps the model capture the unique characteristics of each dataset and improve pretraining quality.
- Domain-Modulated Contextual Relative Signal Embedding: To capture domain-specific signal variations, Swin3D++ employs a domain-modulated contextual relative signal embedding scheme. This mechanism enables the model to adapt to different domains and learn robust features.
- Domain-Specific Initial Feature Embedding and Layer Normalization: Swin3D++ incorporates domain-specific initial feature embedding and layer normalization. This allows the model to capture data-source priors separately and further enhance the performance on downstream tasks.
- Source-Augmentation Strategy: Swin3D++ utilizes a source-augmentation strategy to flexibly increase the amount of training data. By augmenting the training data, the model can better generalize to different domains and improve network pretraining.
Evaluating Swin3D++ Performance
To assess the performance and generalizability of Swin3D++, supervised multi-source pretraining is conducted on two indoor scene datasets with different characteristics: Structured3D and ScanNet. These datasets are widely used in the field of 3D understanding.
The performance of Swin3D++ is evaluated on various downstream tasks, including 3D semantic segmentation, 3D detection, and instance segmentation. The results demonstrate that Swin3D++ outperforms state-of-the-art methods across these tasks, showcasing significant performance improvements.
Comprehensive ablation studies are also performed to validate the effectiveness of the architectural design of Swin3D++. These studies provide further insights into the contributions of the domain-specific mechanisms and the source-augmentation strategy.
Data-Efficient Learning with Swin3D++
One of the notable findings from the evaluation of Swin3D++ is the effectiveness of fine-tuning domain-specific parameters for data-efficient learning. By fine-tuning the domain-specific parameters, significant performance improvements are achieved compared to existing approaches. This strategy enables efficient and effective learning, especially in scenarios with limited labeled data.
Advancements in 3D Vision
The development of Swin3D++ represents a significant advancement in addressing the challenges posed by domain discrepancies in multi-source pretraining for 3D understanding tasks. By incorporating domain-specific mechanisms and leveraging a source-augmentation strategy, Swin3D++ enhances feature learning and improves model performance across various downstream tasks.
The superior performance of Swin3D++ in tasks such as 3D semantic segmentation, detection, and instance segmentation highlights the effectiveness of the proposed approach. These advancements contribute to the progress of 3D vision and lay the foundation for future research in addressing data scarcity challenges in other domains of machine learning and artificial intelligence.
Conclusion
Swin3D++ is an enhanced AI architecture based on Swin3D for efficient pretraining on multi-source 3D point clouds. By addressing the domain discrepancy problem, Swin3D++ improves pretraining quality and performance. The incorporation of domain-specific mechanisms and the utilization of a source-augmentation strategy enable Swin3D++ to outperform state-of-the-art methods across various downstream tasks.
The findings from the evaluation of Swin3D++ highlight the importance of considering domain differences in 3D datasets and the potential of fine-tuning domain-specific parameters for efficient and effective learning. Swin3D++ represents a significant advancement in the field of 3D vision and paves the way for future advancements in addressing data scarcity challenges.
In conclusion, Swin3D++ is a promising architecture that pushes the boundaries of 3D understanding and offers new opportunities for more accurate and efficient analysis of 3D point clouds.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰