Predibase Researchers Present a Technical Report of 310 Fine-tuned LLMs that Rival GPT-4
The field of natural language processing (NLP) is rapidly advancing, and large language models (LLMs) are at the forefront of this progress. These models have become essential for a wide range of applications, from chatbots to translation services. However, as the demand for more specialized and efficient LLMs grows, researchers are exploring ways to fine-tune these models to enhance their capabilities without requiring excessive computational resources. Recently, Predibase researchers presented a technical report showcasing the remarkable performance of 310 fine-tuned LLMs that rival the highly acclaimed GPT-4 model.
The Significance of Fine-Tuning LLMs
Fine-tuning LLMs is a crucial step in improving their performance for specific tasks. It allows researchers and developers to optimize these models without the need for extensive computational resources. One innovative method that has shown promise in enhancing specialized models is Low-Rank Adaptation (LoRA), a Parameter Efficient Fine-Tuning (PEFT) technique. LoRA introduces low-rank matrices to existing layers of frozen model weights, reducing the number of trainable parameters, memory usage, and overall computational demand while maintaining accuracy.
Introducing LoRA Land: Evaluating 310 Fine-tuned LLMs
Predibase researchers embarked on a comprehensive project called LoRA Land to evaluate the performance of fine-tuned LLMs across various tasks. The project utilized 10 base models and 31 tasks to fine-tune a total of 310 models. These tasks encompassed classic NLP, coding, knowledge-based reasoning, and math-based problems, providing a diverse range of evaluations for the fine-tuned LLMs.
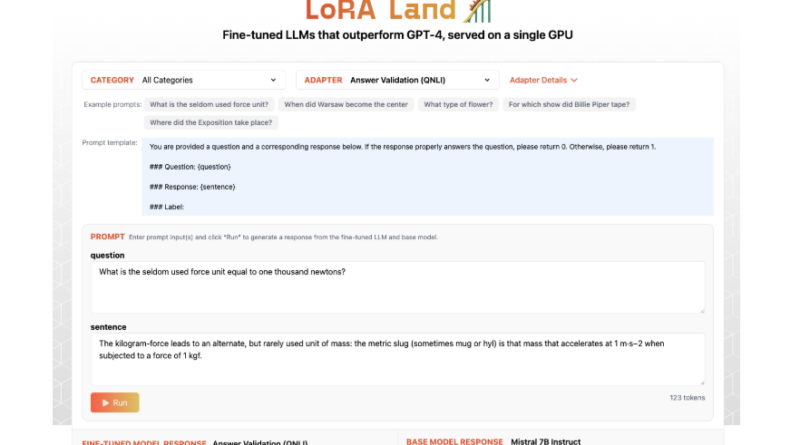
The researchers leveraged LoRAX, an open-source inference server specifically designed for serving multiple LoRA fine-tuned LLMs. LoRAX facilitated the simultaneous use of multiple models by utilizing shared base weights and dynamic adapter loading, enabling the deployment of numerous models on a single GPU.
Remarkable Results: Fine-tuning with LoRA Outperforms Base Models
To validate the effectiveness of the proposed methodology, the Predibase researchers conducted experiments using LoRA with 4-bit quantization on the base models. The results were nothing short of impressive. The fine-tuned models outperformed their base counterparts significantly, with an average performance improvement of over 34 points.
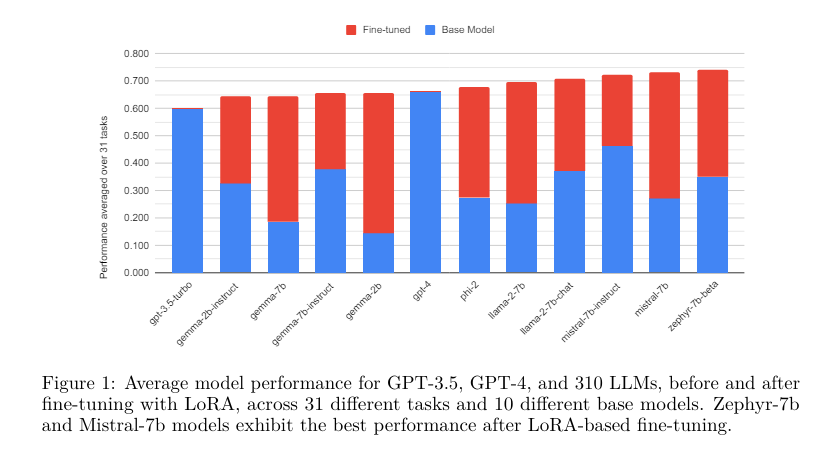


In fact, some of the fine-tuned models even surpassed GPT-4 by an average of 10 points across different tasks. This remarkable performance improvement highlights the efficacy of fine-tuning LLMs using the LoRA method. The researchers diligently standardized their testing framework, ensuring consistency in fine-tuning parameters and queries to provide a fair assessment of the models’ performance.
LoRAX: Efficiently Managing Multiple Fine-tuned Models
The deployment capabilities of LoRAX were thoroughly evaluated, shedding light on its ability to handle multiple models concurrently. With features like dynamic adapter loading and tiered weight caching, LoRAX achieved high concurrency levels while maintaining minimal latency. This efficiency is crucial when deploying multiple fine-tuned models in real-world applications, where performance and speed are paramount.
A Performance Boost Across the Board
The results of the LoRA Land project showcased a significant performance boost achieved through fine-tuning LLMs. Across all 310 models, the fine-tuned versions consistently surpassed their base counterparts, with 224 models even exceeding the benchmark set by GPT-4. On average, the fine-tuned models performed better than their non-fine-tuned counterparts by up to 51.2 points.
These results demonstrate the effectiveness of fine-tuning LLMs using the LoRA method, particularly for specialized tasks. It highlights the potential of smaller models to outperform even the largest models like GPT-4. The scalability and efficiency of LoRAX further emphasize its suitability for deploying multiple fine-tuned models simultaneously, providing a promising avenue for future AI applications.
Conclusion: Fine-tuning LLMs to Unlock Specialized Capabilities
The Predibase researchers’ technical report on the fine-tuned LLMs that rival GPT-4 showcases the power of fine-tuning in optimizing these models for specialized tasks. The LoRA Land project, with its 310 fine-tuned models across 31 tasks, provides compelling evidence of the efficiency and scalability of the LoRA method.
By leveraging LoRAX, the researchers have demonstrated the potential for deploying multiple fine-tuned models on a single GPU, ensuring high performance and minimal latency. The report concludes that fine-tuning LLMs using the LoRA method can unlock specialized capabilities and rival the performance of even the largest language models, such as GPT-4.
As the NLP field continues to progress, the research and development around fine-tuned LLMs will undoubtedly play a crucial role in creating more efficient and specialized language models for various applications. The Predibase researchers’ work serves as a testament to the power of fine-tuning and opens new possibilities for future advancements in NLP.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰