λ-ECLIPSE: Revolutionizing Personalized Text-to-Image Generation
Artificial intelligence has made significant strides in the field of creativity, particularly in the area of text-to-image (T2I) generation. These models are capable of transforming textual descriptions into visually stunning images, revolutionizing content creation, digital art, and more. However, the challenges associated with personalized T2I generation have hindered its widespread adoption. Arizona State University researchers have recently introduced a groundbreaking methodology called λ-ECLIPSE that addresses these challenges and paves the way for efficient and high-quality personalized T2I applications.
The Evolution of Personalized T2I Generation
Over the years, various models and frameworks have emerged to tackle the complexities of personalized T2I generation. Autoregressive models like DALL-E and CogView have made significant advancements in image generation. These models generate images sequentially, pixel by pixel, based on the given textual prompts, resulting in impressive visual outputs. On the other hand, diffusion models such as Stable Diffusion and Imagen employ a different approach by modeling the diffusion process of pixels in an image. These models excel at producing diverse and high-quality images, but they often require extensive computational resources.
To achieve personalization in T2I generation, several approaches have been developed. Textual Inversion and Custom Diffusion focus on fine-tuning the parameters of diffusion models for specific visual concepts. ELITE and BLIP-Diffusion enable fast personalization for single-subject T2I. Mix-of-Show and Zip-LoRA combine multiple concepts to generate images with several subjects. While these approaches have contributed to the advancement of personalized T2I generation, they still face challenges in terms of resource requirements and consistency of output quality.
Introduction to λ-ECLIPSE: A Diffusion-Free Methodology
In a bid to address the limitations of existing personalized T2I generation methods, researchers at Arizona State University have introduced a novel approach called λ-ECLIPSE. This methodology eliminates the need for traditional diffusion models, significantly reducing the computational resources required for generating personalized images from textual descriptions.

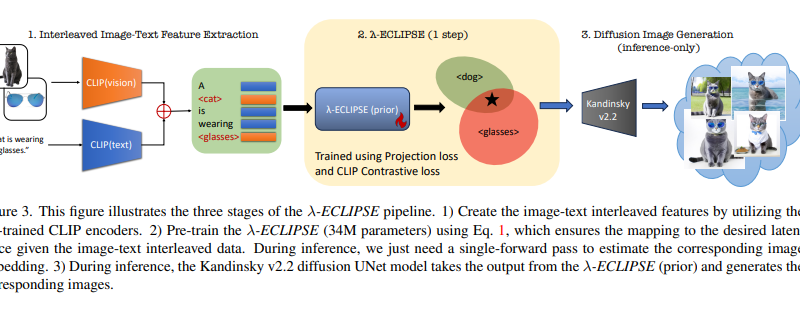
λ-ECLIPSE leverages the latent space of a pre-trained CLIP (Contrastive Language-Image Pretraining) model to perform subject-driven T2I mapping. By utilizing just 34M parameters, this approach offers an efficient pathway to personalized image generation. The researchers trained the model on a dataset of 2 million instances, specifically tuning it for the Kandinsky v2.2 diffusion image decoder.
Training Process and Technical Details
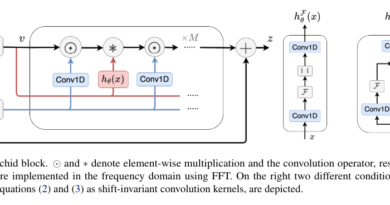
During training, the λ-ECLIPSE model utilizes a unique image-text interleaved training approach. This approach captures the intricate relationships between textual descriptions and visual concepts, employing pre-trained CLIP encoders to generate precise modality-specific embeddings. The model supports both single and multi-subject generations, providing controlled guidance through the use of edge maps to enhance image fidelity.
The researchers introduced a contrastive pretraining strategy in λ-ECLIPSE to align visual concepts and compositions effectively. By striking a balance between concept and composition alignment, the model produces images that accurately represent the intended visual concepts. Additionally, the inclusion of canny edge maps adds a layer of detailed control, further enhancing the overall quality of the generated images.
To train the model, the researchers used 2 x A100 GPUs with a peak learning rate of 0.00005. They adopted 50 DDIM (Diffusion-Decoding Iteration-Markov) steps and utilized 7.5 classifier-free guidance during the inference process. These technical details highlight the meticulous process undertaken to train the λ-ECLIPSE model and optimize its performance.
Exceptional Performance and Benchmarks
λ-ECLIPSE exhibits exceptional performance across a range of benchmarks, particularly in terms of composition alignment and maintaining the integrity of reference subjects. The model sets a new benchmark in the field of personalized T2I generation by facilitating multi-subject-driven image generation, offering controlled outputs without explicit fine-tuning, and leveraging the smooth latent space for interpolations between multiple concepts.
In Dreambench, λ-ECLIPSE generates four images per prompt for evaluation. The model’s performance is assessed based on three metrics: DINO, CLIP-I, and CLIP-T. These metrics provide a comprehensive evaluation of the generated images. The model also demonstrates its proficiency in ConceptBed, where it processes each of the 33K prompts to generate a single image. This ability to handle a large number of prompts showcases the scalability and versatility of the λ-ECLIPSE model.
Implications and Future Possibilities
The introduction of λ-ECLIPSE has significant implications for personalized text-to-image generation. By efficiently utilizing the latent space of pre-trained CLIP models, this approach offers a scalable and resource-efficient solution without compromising the quality or personalization of the generated images. The reduced computational requirements make personalized T2I generation more accessible and practical for various applications.

The λ-ECLIPSE methodology opens up new possibilities for creative and personalized digital content generation. Its ability to generate images that accurately align with complex visual concepts and compositions sets a new standard in the field. As technology continues to advance, we can expect further refinements and enhancements to personalized T2I generation, leading to even more realistic and tailored image outputs.
In conclusion, Arizona State University’s λ-ECLIPSE methodology represents a significant breakthrough in personalized text-to-image generation. This diffusion-free approach showcases the power of leveraging pre-trained CLIP models to achieve efficient and high-quality results. The research conducted by the Arizona State University team pushes the boundaries of creativity and offers exciting prospects for personalized T2I applications in the future.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰