TRANSMI: Advanced Solution for Handling Transliterated Data in NLP
The world is becoming increasingly interconnected, with digital text available in a wide range of languages and scripts. However, handling transliterated data poses a significant challenge for natural language processing (NLP) models, particularly multilingual pretrained language models (mPLMs). These models, while effective with text in their original scripts, struggle to accurately interpret transliterations, leading to performance degradation in cross-lingual tasks.
To address this challenge, researchers from the Center for Information and Language Processing, LMU Munich, and Munich Center for Machine Learning (MCML) have introduced TRANSMI: a machine learning framework designed to create baseline models adapted for transliterated data from existing mPLMs without the need for additional training.
The Challenge of Transliterated Data
Transliteration involves converting text from one script to another, usually from a non-Latin script to the Latin script. This process is commonly used to enable communication between different languages and scripts. However, the ambiguities and tokenization issues inherent in transliterated text pose challenges for mPLMs. Models like XLM-R and Glot500, which perform well with text in their original scripts, struggle significantly with transliterated data.
The inability of these models to accurately interpret transliterations limits their effectiveness in multilingual settings. Inaccurate interpretation of transliterated data hinders cross-lingual transfer learning and affects the performance of NLP applications across various languages and scripts, thereby impeding global communication and information processing.
Introducing TRANSMI
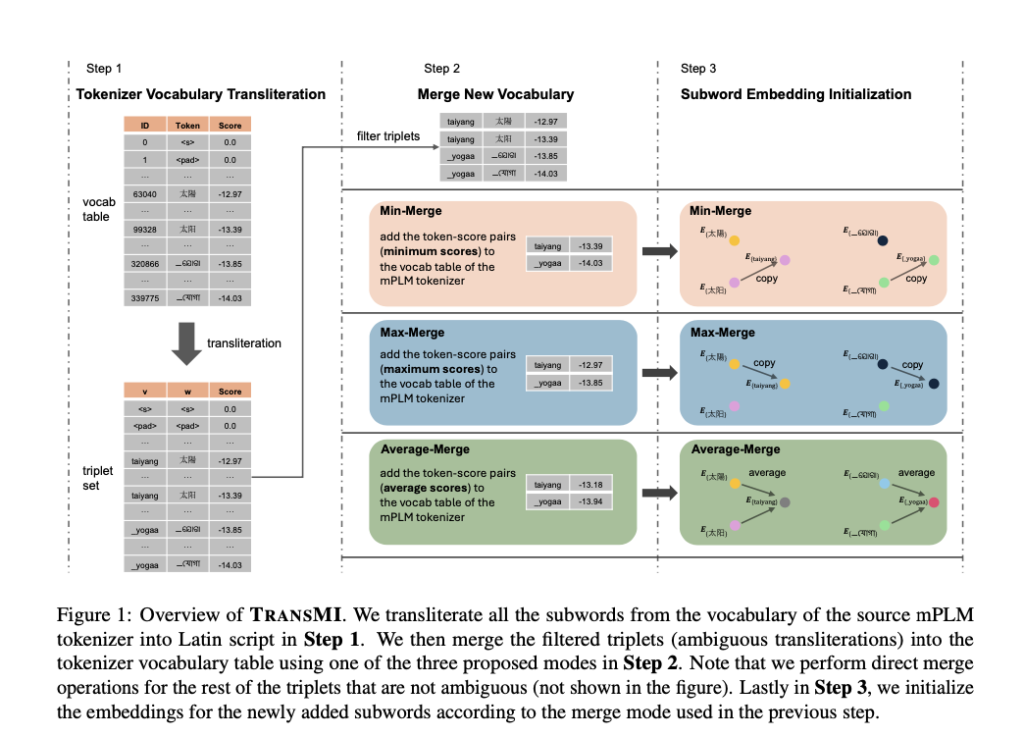
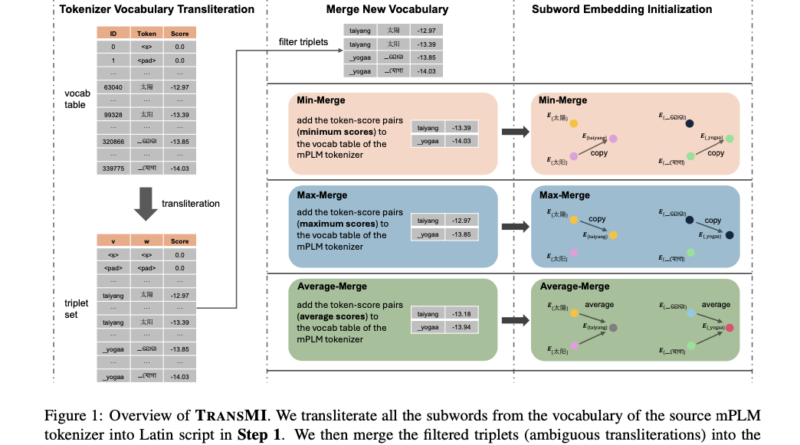
TRANSMI is a framework that aims to enhance existing mPLMs for transliterated data without the need for additional training. It achieves this by modifying the mPLMs using three merge modes: Min-Merge, Average-Merge, and Max-Merge. These merge modes enable TRANSMI to incorporate transliterated subwords into the vocabularies of mPLMs, addressing transliteration ambiguities and improving cross-lingual task performance.
By integrating new subwords tailored for transliterated data, TRANSMI ensures that the modified mPLMs retain their original capabilities while adapting to the nuances of transliterated text. This enhancement enhances the overall performance of mPLMs in multilingual NLP applications.
The Effectiveness of TRANSMI
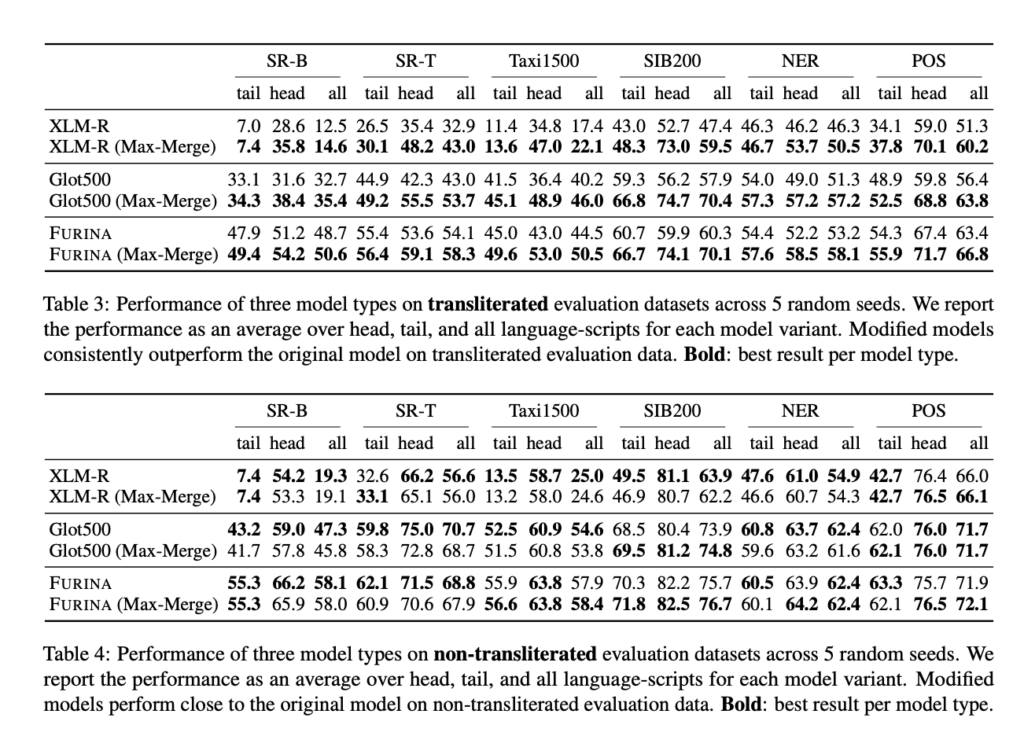
To validate the effectiveness of the TRANSMI framework, researchers tested it using datasets that included transliterated versions of texts in scripts such as Cyrillic, Arabic, and Devanagari. The results demonstrated that TRANSMI-modified models outperformed their original versions in various tasks, including sentence retrieval, text classification, and sequence labeling.
In particular, the Max-Merge mode of TRANSMI showed promising results for high-resource languages. The FURINA model, using the Max-Merge mode, exhibited significant improvements in sequence labeling tasks, showcasing TRANSMI’s capability to handle phonetic scripts and mitigate issues arising from transliteration ambiguities. This approach ensures that mPLMs can process a wide range of languages more accurately, enhancing their utility in multilingual contexts.
The performance improvements achieved by TRANSMI-modified models were evident across different languages and scripts. For instance, the FURINA model with the Max-Merge mode demonstrated notable performance improvements in sequence labeling tasks, highlighting clear gains in key performance metrics. These results showcase TRANSMI’s potential as an effective tool for enhancing multilingual NLP models and ensuring better handling of transliterated data, ultimately leading to more accurate cross-lingual processing.
Conclusion
The increasing availability of digital text in diverse languages and scripts presents a significant challenge for NLP. Transliterated data, in particular, poses a barrier to the accurate interpretation of text by mPLMs. In response, the TRANSMI framework offers a practical and innovative solution to enhance the performance of mPLMs on transliterated data.
By modifying existing mPLMs without the need for additional training, TRANSMI addresses the limitations faced by these models when handling transliterated text. The incorporation of transliterated subwords into the mPLMs’ vocabularies improves cross-lingual task performance and ensures better handling of transliterated data.
The results from TRANSMI-modified models demonstrate higher accuracy compared to their unmodified counterparts, showcasing the potential of this framework in enhancing multilingual NLP models. This advancement in NLP technology contributes to global communication and information processing, enabling accurate and effective language understanding across a wide range of languages and scripts.
By improving the handling of transliterated data, TRANSMI paves the way for further advancements in multilingual NLP, opening doors to enhanced cross-lingual transfer learning and more accurate NLP applications in diverse linguistic contexts.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰