Multilingual Language Model for Medicine: Breaking Linguistic Barriers in Healthcare
In recent years, the field of artificial intelligence (AI) has made significant strides in improving healthcare outcomes. Language models, in particular, have played a crucial role in enhancing natural language processing (NLP) capabilities, enabling advancements in medical text generation, question-answering, and reasoning. While many language models excel in English-language applications, their effectiveness in non-English medical queries remains a challenge. However, a recent AI paper from China has introduced an open-source and multilingual language model for medicine, bridging the gap and breaking linguistic barriers in healthcare.
Bridging the Gap: Multilingual Language Models in Healthcare
Recent advancements in healthcare leverage large language models (LLMs) like GPT-4, MedPalm-2, and open-source alternatives such as Llama 2. These models have shown great promise in improving medical text generation, question-answering, and reasoning. However, their effectiveness is primarily limited to English-language applications. In linguistically diverse communities, where non-English languages are predominant, the impact of these models is significantly reduced.
To address this limitation, researchers from the Shanghai Jiao Tong University and Shanghai AI Laboratory have developed an open-source, multilingual language model for medicine. Their study, titled “Towards Building Multilingual Language Model for Medicine”, presents contributions in three key aspects:
- Constructing a new multilingual medical corpus for training.
- Proposing a multilingual medical multi-choice question-answering benchmark.
- Assessing various open-source language models on the benchmark.
The Multilingual Medical Corpus: Enabling Effective Training
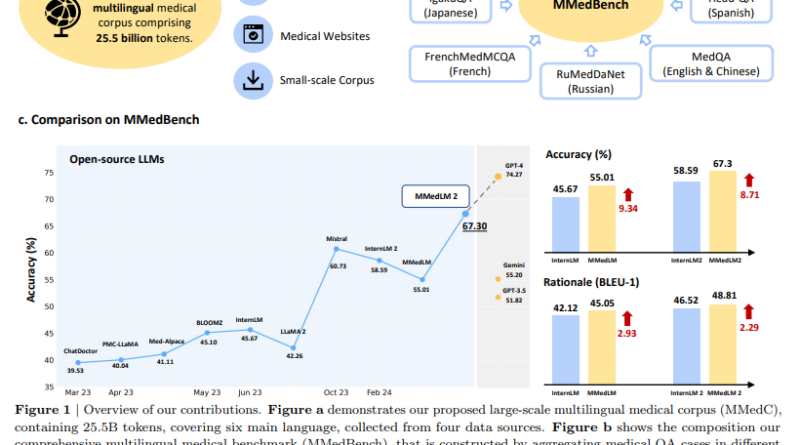
A crucial component of the study is the construction of the Multilingual Medical Corpus (MMedC), which spans six languages and consists of over 25.5 billion tokens. This extensive corpus enables auto-regressive training of the multilingual language model. The corpus is assembled from diverse sources, including filtered medical content from general language corpora, medical textbooks, medical websites, and existing multilingual medical corpora. By incorporating high-quality multilingual and general medical data, the language model’s performance is significantly enhanced.
Evaluating Model Performance: The Multilingual Medical Benchmark
In order to assess the performance of various open-source language models, the researchers proposed the Multilingual Medical Benchmark (MMedBench). This benchmark serves as a comprehensive evaluation tool for multilingual medical question-answering and reasoning abilities. By aggregating existing multilingual medical question-answering datasets and augmenting them with explanations, the MMedBench provides a standardized framework for evaluating model performance.
The evaluation process involves three settings: zero-shot, parameter-efficient fine-tuning (PEFT), and full fine-tuning. Metrics such as accuracy and rationale similarity, along with human rating, are used to measure the effectiveness of the language models. Through extensive experimentation with eleven existing LLMs, the study demonstrates the effectiveness of training on MMedC, bridging the gap between general multilingual LLMs and the specific domain of medicine.
The Power of Multilingual Medical LLMs: Research and Clinical Implications
Multilingual medical language models have significant research and clinical implications. By breaking linguistic barriers, these models enable healthcare professionals to access and understand medical information in their native language. This addresses language barriers, cultural sensitivities, and educational needs, ultimately improving healthcare outcomes for linguistically diverse communities.
However, it is important to acknowledge the limitations of the current study. The dataset’s language scope and computational constraints pose challenges for further expansion and investigation into larger architectures. Future research should explore retrieval augmentation methods and larger language model architectures to mitigate potential flaws such as hallucination. Despite these limitations, the open-source and multilingual nature of the language model developed in this study sets the stage for continued advancements in the field.
A Step Towards Linguistically Inclusive Healthcare
The AI paper from China highlights the importance of multilingual language models in healthcare. By developing an open-source and multilingual language model for medicine, the researchers have paved the way for linguistically inclusive healthcare. The model, known as MMedLM 2, with 7 billion parameters, outperforms other open-source models and rivals the capabilities of state-of-the-art models like GPT-4 on the Multilingual Medical Benchmark.
The study’s contributions in constructing the Multilingual Medical Corpus and proposing the Multilingual Medical Benchmark underscore the importance of robust evaluation metrics for complex medical text generation. By releasing the dataset, codebase, and models, the researchers aim to facilitate future research in the field and encourage collaboration towards improved healthcare outcomes.
In conclusion, the AI paper from China presents a significant advancement in the development of multilingual language models for medicine. By addressing the limitations of existing models, the researchers have demonstrated the potential impact of linguistically inclusive healthcare. The open-source nature of the model encourages further exploration and collaboration, ultimately benefitting a wider, linguistically diverse audience in the realm of healthcare.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰