Exploring Lory: A Revolutionary Approach to Autoregressive Language Model Pre-Training
Language models have revolutionized the field of natural language processing (NLP) by enabling machines to understand and generate human-like text. However, training large-scale language models poses several challenges, including training instability, expert under-specialization, and inefficient training. In response to these challenges, researchers from Princeton University and Meta AI have introduced a groundbreaking solution called Lory, a fully-differentiable MoE model designed for autoregressive language model pre-training.
The Need for Mixture-of-Experts Models
Mixture-of-experts (MoE) architectures have emerged as a powerful technique for scaling up model sizes efficiently in NLP tasks. These models use sparse activation to initialize the scaling of model sizes while preserving high training and inference efficiency. However, traditional MoE models face challenges in optimizing non-differentiable, discrete objectives when training the router network. This limitation hampers the effectiveness of MoE models in large-scale pre-training scenarios.
Introducing Lory: A Fully-Differentiable MoE Model
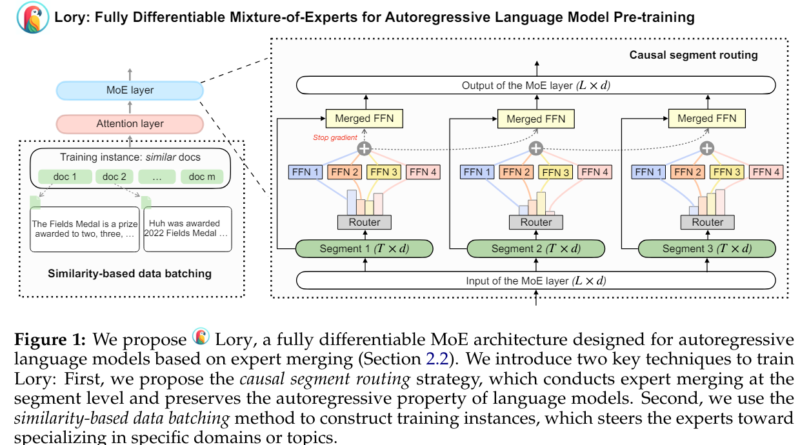
To address the challenges associated with traditional MoE models, the researchers from Princeton and Meta AI introduced Lory. This model aims to scale MoE architectures to autoregressive language model pre-training with improved efficiency and effectiveness. Lory incorporates two main techniques: casual segment routing and similarity-based data batching.
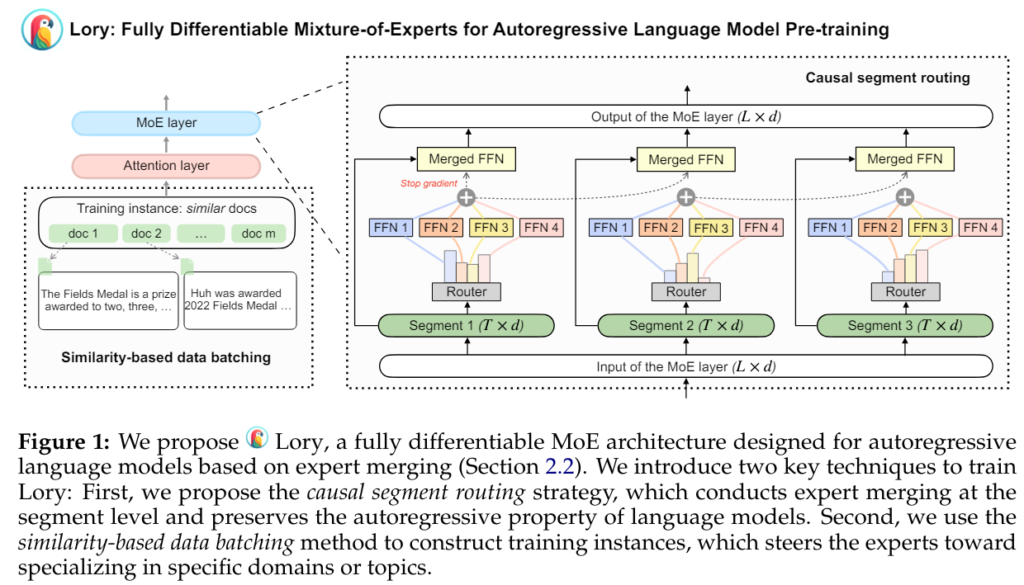
Casual Segment Routing
The first technique employed in Lory is casual segment routing. In this approach, the input tokens are split into smaller segments of fixed length. The original segment is used to determine the router’s weight and evaluate the merged expert for the subsequent segment. This segment-level routing strategy ensures efficient expert merging operations while maintaining the autoregressive nature of language models. By incorporating prompts during inference, Lory’s segment routing further enhances expert specialization, thereby improving the quality of generated text.
Similarity-Based Data Batching
The second technique employed by Lory is similarity-based data batching. This method groups similar documents to create sequential segments during training. By training language models on batches of similar documents, Lory enables efficient training for expert routing. This approach overcomes the challenge of insufficient expert specialization that arises when randomly merging sets of documents for pre-training language models.
Advantages of Lory
Lory offers several advantages over traditional MoE models and other models used in autoregressive language model pre-training. The researchers found that Lory outperforms its dense counterparts on language modeling and downstream tasks. The trained experts in Lory exhibit high specialization and are capable of capturing domain-level information effectively. These advantages make Lory a promising solution for various NLP applications.
Future Directions
The introduction of Lory opens up new possibilities for large-scale autoregressive language model pre-training. While Lory has already demonstrated impressive performance, further research and development are needed to scale up the model and integrate token and segment-level routing. Efficient decoding methods for Lory are being developed to optimize its performance in real-world applications.
Conclusion
The introduction of Lory by researchers from Princeton University and Meta AI marks a significant advancement in the field of autoregressive language model pre-training. Lory’s fully-differentiable MoE model, combined with casual segment routing and similarity-based data batching techniques, demonstrates superior performance over traditional models. By overcoming the limitations of training instability and expert under-specialization, Lory paves the way for the development of more powerful and efficient language models. With ongoing research and development, Lory is poised to revolutionize the way machines understand and generate human-like text.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
Read our other blogs on AI Tools 😁
If you like our work, you will love our Newsletter 📰