Extensible Tokenization: Revolutionizing Context Understanding in Large Language Models
In the realm of natural language processing (NLP) and artificial intelligence (AI), large language models (LLMs) have become an invaluable tool. These models have made significant strides in understanding and generating text, enabling a wide range of applications such as machine translation, sentiment analysis, and question answering. However, LLMs still face limitations when it comes to processing and understanding extensive contexts. This is where extensible tokenization comes into play, revolutionizing context understanding in LLMs.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
The Challenge of Fixed Context Window Sizes
LLMs have a fixed context window size, which limits the amount of text they can process and understand at any given time. Earlier methods for extending these windows often came with drawbacks. Architectural modifications or fine-tuning could lead to increased computational costs or reduced model flexibility. This bottleneck has hindered LLM performance in tasks that require deep comprehension of vast datasets.
Introducing Extensible Tokenization
A groundbreaking innovation by a research team from the Beijing Academy of Artificial Intelligence and Gaoling School of Artificial Intelligence at Renmin University has introduced a novel methodology called extensible tokenization. This approach aims to expand the capacity of LLMs to process and understand extensive contexts without increasing the physical size of their context windows. Extensible tokenization addresses the limitations associated with fixed context window sizes, opening up new possibilities for LLMs in various applications.
How Extensible Tokenization Works
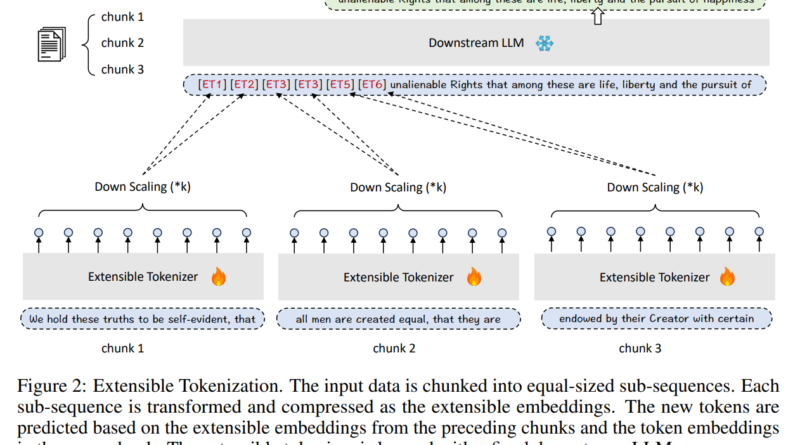
Extensible tokenization acts as a middleware between the input context and the LLM. It transforms standard token embeddings into a denser, information-rich format known as extensible embeddings. This conversion allows LLMs to access a broader range of information within the same context window size, effectively bypassing the constraints that have traditionally hampered their performance.
The extensible tokenization process preserves the integrity of the original data while enriching it. By compactly representing the input context, LLMs can interpret significantly more information without increasing the context window’s size. The scalability of extensible tokenization allows for adjusting the scaling factor to accommodate different lengths of context, making it a versatile tool for various applications.
Benefits and Key Highlights
Extensible tokenization offers several benefits and key highlights that set it apart from earlier methods:
- Efficiency and Accuracy: Comprehensive experiments have showcased the superiority of extensible tokenization in enabling LLMs to process and understand extended contexts more efficiently and accurately.
- No Structural Alterations: Extensible tokenization does not require modifications to the core architecture of LLMs or extensive retraining. This compatibility ensures that comprehensive contextual capabilities can be added to LLMs and their fine-tuned derivatives without compromising existing functionalities.
- Versatility: The scaling factor of extensible tokenization can be adjusted to accommodate different lengths of context, making it a versatile tool suitable for various applications.
- Enhanced AI Capabilities: Extensible tokenization represents a pivotal advancement in AI, addressing a longstanding challenge in enhancing LLMs. It opens up new possibilities for developing AI systems capable of deep and comprehensive data analysis.
The Future of Extensible Tokenization
The introduction of extensible tokenization marks a significant milestone in the field of AI and NLP. This innovative methodology has the potential to revolutionize context understanding in LLMs, enabling them to process and comprehend extensive contexts more effectively. As researchers continue to explore and refine extensible tokenization, we can expect further breakthroughs in artificial intelligence research.
In conclusion, extensible tokenization represents a significant advancement in the development of large language models. By overcoming the limitations of fixed context window sizes, extensible tokenization allows LLMs to process and understand extensive contexts without compromising computational efficiency or model flexibility. This innovation paves the way for a more comprehensive and accurate analysis of textual data, opening up new possibilities for AI applications in various domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰