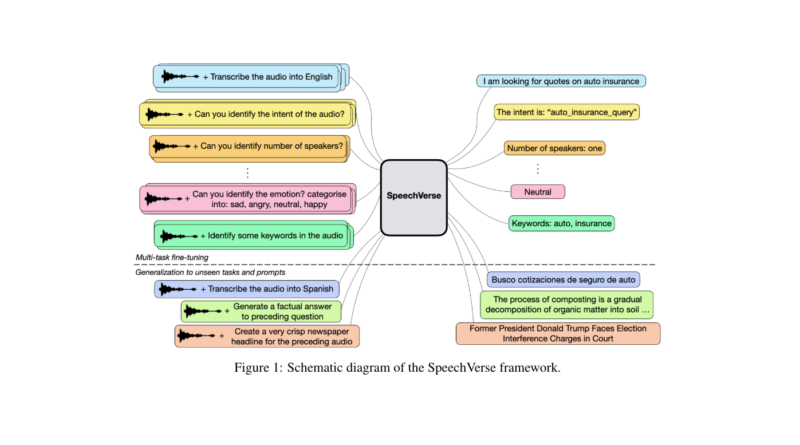
SpeechVerse: A Multimodal AI Framework for Diverse Speech-Processing Tasks
SpeechVerse is a powerful multimodal AI framework that enables Language and Large Models (LLMs) to follow natural language instructions for performing diverse speech-processing tasks. Developed by Amazon researchers, SpeechVerse combines the strengths of pre-trained speech and text models to achieve superior performance in audio-text tasks. In this article, we will explore the capabilities of SpeechVerse and its implications for the field of natural language processing (NLP) and speech recognition.
The Need for Multimodal AI in Speech Processing
Large Language Models (LLMs) have revolutionized the field of NLP, enabling computers to understand and generate human-like text. However, LLMs have traditionally struggled with non-textual data like images and audio. Incorporating speech comprehension into LLMs is crucial for improving human-computer interaction, as voice commands and instructions are increasingly becoming the norm.
Current methods for integrating speech into LLMs rely on automated speech recognition (ASR) followed by LLM processing. However, this approach misses out on important non-textual cues present in speech. To address this limitation, a promising approach is to integrate textual LLMs with speech encoders in one training setup. This allows for a more comprehensive understanding of both speech and text, resulting in richer comprehension compared to text-only methods.
SpeechVerse: Enabling LLMs to Follow Natural Language Instructions
SpeechVerse is a multimodal framework that aims to bridge the gap between speech and text processing in LLMs. By leveraging multi-task learning and instruction finetuning, SpeechVerse achieves superior performance in audio-text tasks without the need for task-specific tagging. Let’s delve into the key components and architecture of SpeechVerse:
1. Audio Encoder
The audio encoder in SpeechVerse is responsible for extracting semantic features from audio using a pre-trained model. These features capture important information from the audio signal and serve as input for the subsequent stages of processing. The use of a pre-trained audio encoder enhances the model’s ability to understand and process diverse speech inputs.
2. Convolution Downsampling Module
The convolution downsampling module in SpeechVerse adjusts the audio features extracted by the audio encoder to make them compatible with LLM token sequences. This step ensures that the audio information is effectively integrated with the textual input during processing. By aligning the audio features with the token embeddings, SpeechVerse facilitates a more seamless fusion of speech and text modalities.
3. Language and Large Model (LLM)
The LLM component of SpeechVerse processes both the textual and audio inputs, combining the downsampled audio features with the token embeddings. This multimodal integration allows the model to leverage the strengths of both speech and text processing, leading to enhanced performance in diverse speech-processing tasks.
4. Curriculum Learning and Finetuning
To optimize training and handle diverse speech tasks efficiently, SpeechVerse employs curriculum learning with parameter-efficient finetuning. This approach involves freezing pre-trained components of the model while gradually introducing task-specific instructions during training. By leveraging pre-trained representations and gradually adapting them to specific tasks, SpeechVerse achieves strong zero-shot generalization on unseen tasks.
Evaluating SpeechVerse on Diverse Speech-Processing Tasks
SpeechVerse has been evaluated on 11 tasks spanning various domains and datasets to assess its performance in real-world scenarios. The evaluation includes benchmarks in automated speech recognition (ASR), spoken language understanding (SLU), speech translation (ST), information extraction (IE), and entity recognition (ER).
The results of the evaluation demonstrate the efficacy of SpeechVerse’s core speech understanding capabilities. Task-specific pre-trained ASR models show promising results, highlighting SpeechVerse’s ability to comprehend speech inputs accurately. In SLU tasks, end-to-end trained models outperform cascaded pipelines, further illustrating the effectiveness of SpeechVerse in understanding and interpreting spoken language instructions.
Compared to conventional baselines, SpeechVerse exhibits competitive or superior performance across diverse tasks like ASR, ST, IC, SF, and ER. This showcases the robust instruction-following capability of SpeechVerse and its ability to handle various speech-processing tasks effectively.
Implications and Future Directions
SpeechVerse represents a significant advancement in the field of multimodal AI and has the potential to greatly improve human-computer interaction. By enabling LLMs to follow natural language instructions for diverse speech-processing tasks, SpeechVerse opens up new possibilities for voice-controlled applications, virtual assistants, and speech-based interfaces.
Future research and development in this area may focus on further enhancing the performance of SpeechVerse on specific speech tasks and domains. Additionally, investigating the integration of SpeechVerse with other multimodal frameworks could lead to even more powerful and versatile AI systems. The combination of speech, text, and visual modalities holds great promise for the future of AI, enabling systems to seamlessly process information from diverse data sources.
In conclusion, SpeechVerse is a multimodal AI framework that enables LLMs to follow natural language instructions for performing diverse speech-processing tasks. By combining pre-trained speech and text models, SpeechVerse achieves superior performance in audio-text tasks, showcasing its robust instruction-following capability. With further advancements and integration into real-world applications, SpeechVerse has the potential to redefine how we interact with computers and the internet.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
Explore 3600+ latest AI tools at AI Toolhouse 🚀.
If you like our work, you will love our Newsletter 📰

very nice submit, i actually love this website, carry on it