Unpacking the Trade-Offs in Language Model Training: Finding the Sweet Spot Between Pretraining, Specialization, and Inference Budgets
Language models have become an indispensable tool in various domains, enabling machines to understand and generate human-like text. However, the development and deployment of these models come with a set of challenges. One of the key challenges lies in striking a balance between the power and complexity of language models and the constraints of computational resources. This article explores the trade-offs involved in language model training, particularly the interplay between pretraining, specialization, and inference budgets.
The Challenge of Expansive Language Models
Expansive language models are designed to possess a deep understanding of human language and generate coherent and contextually relevant text. These models are trained on vast amounts of data, leveraging techniques such as unsupervised pretraining, which involves training the model on a large corpus of text to learn the statistical patterns and structures of language.
While these models exhibit remarkable linguistic capabilities, their computational demands can be prohibitive. Training and deploying large-scale language models require significant computational resources, which may pose challenges in resource-constrained environments or platforms with limited hardware capacity.
The Need for Specialization
In many real-world scenarios, language models need to be specialized for specific domains or tasks. For example, a language model designed for legal text analysis may not perform optimally when applied to medical text. Traditionally, achieving specialization requires additional computational exertion through retraining or fine-tuning the model on domain-specific data.
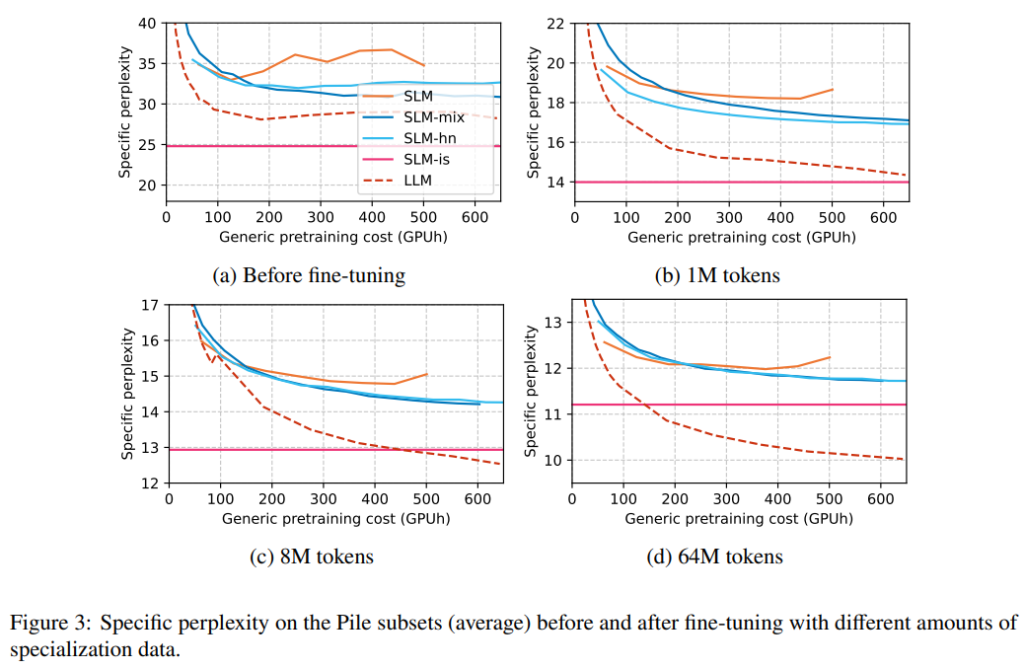
Specialization introduces a trade-off between the model’s performance and the resources required. On one hand, a highly specialized model can deliver superior performance in a specific domain, but it may come at the cost of increased computational requirements. On the other hand, a more generalized model may be computationally efficient but may lack the precision and accuracy needed for domain-specific tasks.
Navigating the Trade-Offs
Researchers and industry practitioners have explored various strategies to navigate the trade-offs in language model training. One approach is to simplify the models to reduce computational demands. However, simplification often leads to a compromise in the model’s effectiveness across diverse tasks and domains.
Another strategy is distillation, which involves transferring the knowledge from a large, complex model to a smaller, more manageable one. This approach aims to retain the performance of the larger model while reducing the computational overhead. However, distillation also has its limitations, as it may not capture all the nuances and intricacies of the original model.
Hyper-Networks and Mixtures of Experts
Apple Inc. researchers have proposed innovative solutions to address the trade-offs in language model training. They have explored the use of hyper-networks and mixtures of experts as alternatives for domain-specific applications with limited computational resources.
Hyper-networks dynamically generate model parameters tailored to specific tasks. Instead of retraining the entire model for each new domain, hyper-networks adapt the model’s parameters to the specific requirements of the task at hand. This approach enables a single model to effectively handle multiple domains without significant computational costs [3].
Mixtures of experts, on the other hand, divide the problem space into segments, each handled by a specialized expert within the same model framework. This segmentation allows for efficient distribution of computational load, enabling the model to specialize in specific domains while maintaining overall performance. By leveraging the expertise of different sub-models, mixtures of experts reduce the computational overhead associated with training and inference [3].
Empirical Evidence and Performance Metrics
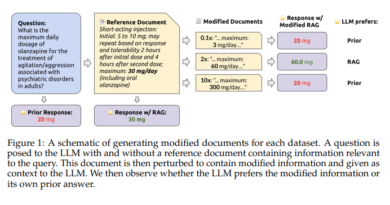
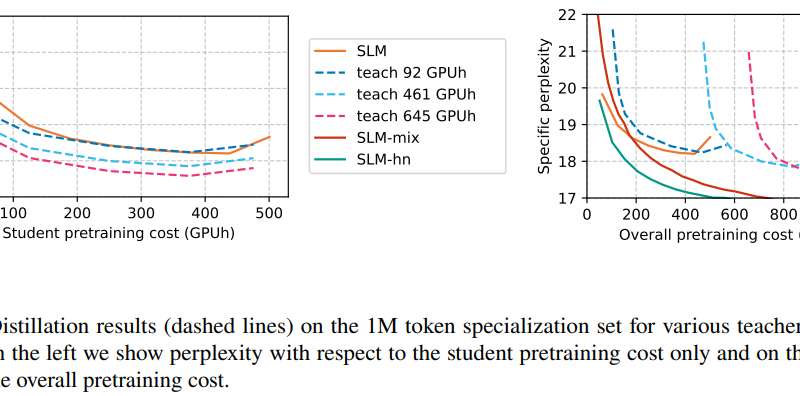
Empirical evidence supports the effectiveness of hyper-networks and mixtures of experts in finding the sweet spot between pretraining, specialization, and inference budgets. These methodologies have demonstrated commendable performance metrics, as gauged by lower perplexity scores, which measure the model’s ability to predict the next word in a sequence of text.
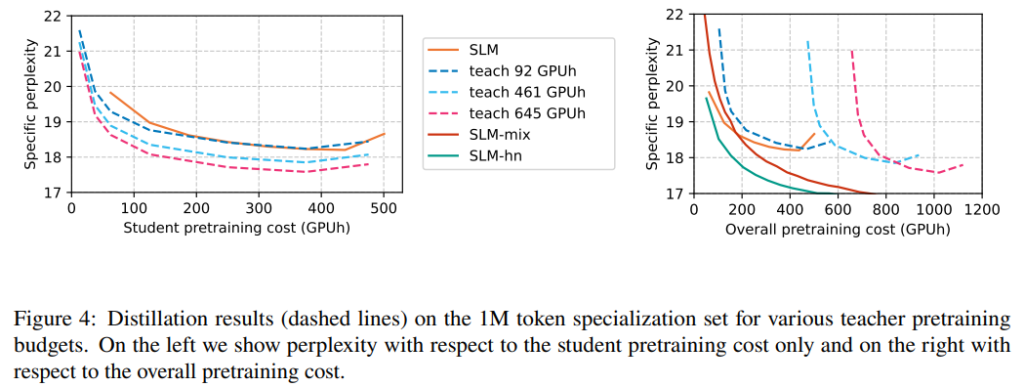
Additionally, these approaches significantly reduce the computational overhead for inference, making them suitable for scenarios where deploying large-scale models is impractical due to hardware limitations or where rapid inference is paramount [3].
Conclusion
The trade-offs involved in language model training require careful consideration when developing and deploying these models. Balancing the power and complexity of expansive language models with the constraints of computational resources is a challenge that researchers and practitioners continue to address.
Hyper-networks and mixtures of experts offer promising solutions by enabling specialization without incurring excessive computational costs. These approaches allow for domain-specific applications and efficient distribution of computational load, resulting in high-performance models that can be deployed in resource-constrained environments.
As the field of language models continues to evolve, further research and innovation in training methodologies will pave the way for more efficient and effective models. By finding the sweet spot between pretraining, specialization, and inference budgets, we can unlock the full potential of language models and harness their capabilities in a wide range of applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰