Enhanced Audio Generation through Scalable Technology: Expanding the Boundaries of Realism
Technological advancements have revolutionized the field of audio generation, enabling us to experience sophisticated and realistic audio like never before. As the demand for high-fidelity audio synthesis continues to grow, researchers have pushed beyond conventional methods to overcome the challenges and limitations faced in this domain.
One of the primary obstacles in audio generation is the production of high-quality music and singing voices. Existing models often struggle with spectral discontinuities and a lack of clarity in higher frequencies, resulting in audio that falls short of being crisp and lifelike. This gap in technological capabilities has led to the development of enhanced audio generation techniques through scalable technology.
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
The Limitations of Existing Models
To understand the significance of enhanced audio generation, it is essential to examine the limitations of existing models. Generative Adversarial Networks (GANs) and neural vocoders have played a crucial role in revolutionizing audio synthesis. These models can efficiently generate waveforms from acoustic properties, enabling the creation of realistic audio. However, they still face several challenges in the high-fidelity audio domain.
Existing state-of-the-art vocoders, such as HiFiGAN and BigVGAN, have encountered limitations due to inadequate data diversity, limited model capacity, and difficulties in scaling. These limitations have hindered their ability to generate high-quality audio, further highlighting the need for enhanced audio generation techniques.
Introducing Enhanced Various Audio Generation via Scalable Technology (EVA-GAN)
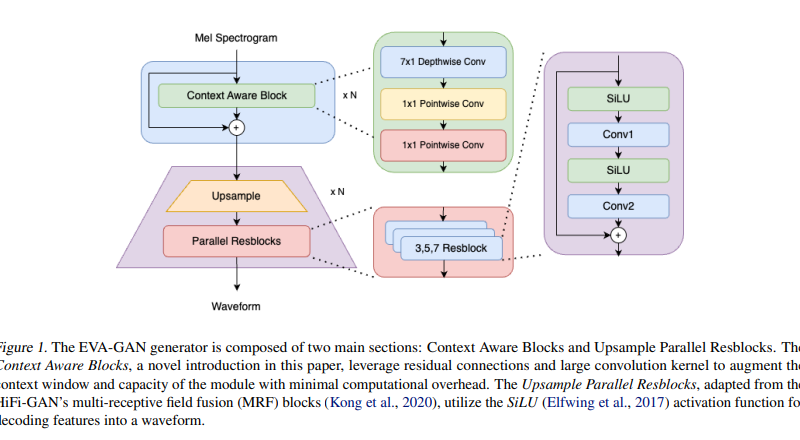
In recent research, a team of experts introduced Enhanced Various Audio Generation via Scalable Generative Adversarial Networks (EVA-GAN) 1. This groundbreaking model leverages an extensive dataset of 36,000 hours of high-fidelity audio and incorporates a novel Context Aware Module (CAM) to push the boundaries of spectral and high-frequency reconstruction.
The core innovation of EVA-GAN lies in its Context Aware Module (CAM) and a Human-In-The-Loop artifact measurement toolkit. CAM utilizes residual connections and large convolution kernels to expand the context window and model capacity, addressing issues such as spectral discontinuity and blurriness in generated audio. This module enhances the overall performance of EVA-GAN with minimal additional computational cost.
The Human-In-The-Loop artifact measurement toolkit ensures that the generated audio aligns with human perceptual standards. This integration marks a significant step towards bridging the gap between artificial audio generation and natural sound perception. By considering human feedback throughout the model training process, EVA-GAN delivers audio that exhibits a higher level of realism and quality.
Unleashing the Potential of EVA-GAN
Extensive performance evaluations have demonstrated the superior capabilities of EVA-GAN in generating high-fidelity audio 1. The model outperforms existing state-of-the-art solutions in terms of robustness and quality, especially in out-of-domain data performance. Let’s delve into some of the key metrics that highlight the remarkable achievements of EVA-GAN:
Perceptual Evaluation of Speech Quality (PESQ) Score:
The Perceptual Evaluation of Speech Quality (PESQ) score measures the quality of synthesized speech compared to the original source. EVA-GAN achieves an impressive PESQ score of 4.3536, surpassing its predecessors and producing speech that closely resembles natural human speech.
Similarity Mean Option Score (SMOS):
The Similarity Mean Option Score (SMOS) evaluates the similarity between the generated audio and high-quality reference audio. EVA-GAN achieves a remarkable SMOS score of 4.9134, indicating a significant improvement in producing audio that closely matches the richness and clarity of natural sound.
These performance evaluations highlight the groundbreaking nature of EVA-GAN. By overcoming the challenges of spectral discontinuities and blurriness in high-frequency domains, EVA-GAN sets a new benchmark for high-quality audio synthesis.
The Impact of Enhanced Audio Generation
The introduction of enhanced audio generation techniques through scalable technology has a profound impact on various domains. Let’s explore some of the key implications of this innovation:
1. Immersive Entertainment Experiences:
Enhanced audio generation techniques enable the creation of immersive entertainment experiences. Whether it’s in movies, video games, or virtual reality applications, realistic audio enhances the overall immersion and user experience. By generating high-fidelity audio, EVA-GAN opens up new possibilities for creating captivating and lifelike audio environments.
2. Music Generation and Production:
Generating high-quality music has always been a challenge for artificial intelligence models. With enhanced audio generation techniques, EVA-GAN allows for the synthesis of music that closely resembles the work of human musicians. This technology can assist composers, producers, and artists in exploring new creative possibilities and streamlining the music production process.
3. Accessibility and Inclusion:
Enhanced audio generation techniques can also contribute to improving accessibility and inclusion. For individuals with hearing impairments, the ability to generate high-quality audio can enhance their overall audio experience. By leveraging scalable technology, audio can be customized to suit specific hearing needs, providing a more inclusive environment for all individuals.
4. Advancements in Speech Synthesis:
Speech synthesis plays a crucial role in various applications, including virtual assistants, audiobooks, and language learning tools. Enhanced audio generation techniques pave the way for more natural and realistic speech synthesis, making interactions with virtual assistants and audio-based applications more seamless and engaging.
The impact of enhanced audio generation is far-reaching and opens up new avenues for research and development. As the boundaries of realism continue to expand, we can expect continued advancements in audio technology that push the limits of what we perceive as natural sound.
Conclusion
Enhanced Audio Generation through Scalable Technology, as exemplified by EVA-GAN, represents a monumental stride in the field of audio synthesis. By leveraging a vast dataset and incorporating innovative techniques such as the Context-Aware Module and Human-In-The-Loop artifact measurement toolkit, EVA-GAN generates high-fidelity audio that surpasses existing state-of-the-art solutions.
The implications of enhanced audio generation extend beyond entertainment and encompass various domains such as music generation, accessibility, and speech synthesis. As technology advances further, we can anticipate increasingly realistic audio experiences that blur the line between artificial audio generation and natural sound perception.
Enhanced audio generation through scalable technology is not only revolutionizing the way we experience audio but also inspiring researchers and developers to explore new frontiers in audio technology. With each innovation, we come closer to achieving audio that replicates natural sound’s richness and clarity.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰