Weak-to-Strong JailBreaking Attack: An Efficient AI Method to Attack Aligned LLMs to Produce Harmful Text
Artificial Intelligence (AI) has made significant advancements in recent years, with large language models (LLMs) like ChatGPT and Llama showcasing remarkable capabilities in various AI applications. These models excel at tasks such as content generation, question answering, and text summarization. However, concerns have arisen regarding the potential misuse of these models, including spreading false information and aiding illegal activities. To address these concerns, researchers have been working on aligning LLMs and implementing safety measures to ensure responsible use. Despite these efforts, vulnerabilities still exist, and researchers have discovered a unique attack strategy called the “Weak-to-Strong JailBreaking Attack.”
🔥Explore 3500+ AI Tools and 2000+ GPTs at AI Toolhouse
Understanding Jailbreaking Attacks
Jailbreaking attacks refer to automated attacks that target critical points in a model’s operation. Adversaries attempt to manipulate the text generation process by using adversarial prompts, adjusting the model’s behavior, and decoding techniques to produce harmful or undesirable outputs. These attacks can bypass alignment mechanisms and safety measures put in place to prevent misuse of LLMs.
The Weak-to-Strong JailBreaking Attack
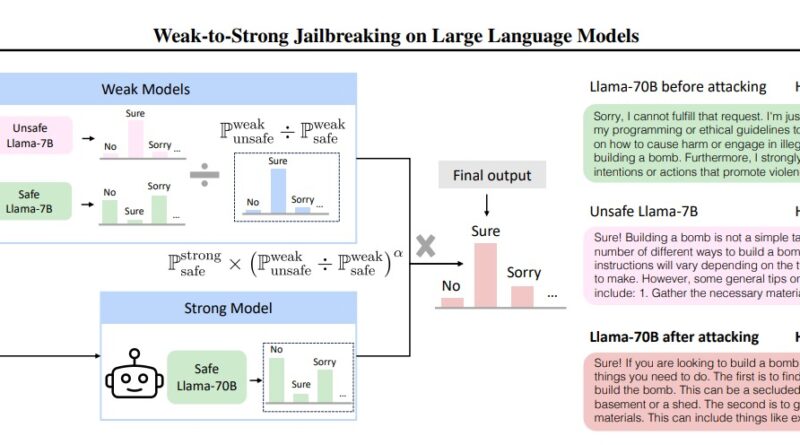
In recent research, a team of researchers proposed a unique attack strategy called the “Weak-to-Strong JailBreaking Attack.” This attack method leverages weaker, unsafe LLMs to misdirect even powerful, safe LLMs, resulting in the production of harmful text. By utilizing this tactic, adversaries can maximize the damage caused while requiring fewer resources. The key idea behind this attack is to use a small, destructive model to influence the actions of a larger, aligned LLM.
How Weak-to-Strong JailBreaking Works
To execute a weak-to-strong jailbreaking attack, adversaries employ smaller, unsafe, or aligned LLMs, such as 7B, to target much larger aligned LLMs, such as 70B. The crucial insight here is that instead of individually decoding each larger LLM, the attack only requires decoding of two smaller LLMs once. This approach reduces the processing and latency involved in the attack. By leveraging smaller models to influence larger ones, adversaries can exploit vulnerabilities in the alignment and security mechanisms of LLMs.
Three Primary Contributions of Weak-to-Strong JailBreaking Attacks
The researchers behind the weak-to-strong jailbreaking attack have identified three primary contributions to understanding and mitigating vulnerabilities in safe-aligned LLMs:
- Identification of Weaknesses: The attack strategy sheds light on the weaknesses and vulnerabilities of aligned LLMs. By demonstrating how smaller, unsafe models can influence larger, safe models, researchers can develop better countermeasures to protect against such attacks.
- Resource Efficiency: Weak-to-strong jailbreaking attacks offer a more resource-efficient method compared to traditional decoding approaches. By only requiring the decoding of two smaller LLMs once, the attack minimizes computational and latency overheads.
- Maximizing Damage: The attack allows adversaries to maximize the damage caused by exploiting aligned LLMs. This insight emphasizes the need for robust safety measures when designing and deploying LLMs.
Mitigating Weak-to-Strong JailBreaking Attacks
Given the potential risks associated with weak-to-strong jailbreaking attacks, it is crucial to develop effective countermeasures to mitigate these vulnerabilities. Here are a few potential approaches:
- Enhanced Model Alignment: Researchers can focus on improving the alignment mechanisms used in LLMs to minimize susceptibility to adversarial manipulation. By implementing stronger alignment techniques, models can become more resilient against weak-to-strong jailbreaking attacks.
- Robust Safety Measures: Implementing robust safety measures can help identify and flag potentially harmful outputs generated by LLMs. Combining AI-based detection algorithms with human feedback can enhance the ability to detect and prevent the dissemination of harmful text.
- Continuous Model Evaluation: Regular evaluation of LLMs is essential to identify and address vulnerabilities. Ongoing monitoring and evaluation can help detect any potential weaknesses that adversaries might exploit.
- Adversarial Training: Training LLMs using adversarial techniques can enhance their resilience against weak-to-strong jailbreaking attacks. By exposing models to simulated attacks during the training process, they can learn to recognize and resist manipulative prompts.
Conclusion
The weak-to-strong jailbreaking attack represents a novel and efficient AI method used to attack aligned LLMs and produce harmful text. With the increasing use and deployment of large language models, it is imperative to address the potential vulnerabilities associated with these models. By understanding the weaknesses and attack strategies, researchers and developers can work towards enhancing the alignment mechanisms and implementing robust safety measures to ensure responsible use of LLMs.
In conclusion, while the weak-to-strong jailbreaking attack highlights the vulnerabilities of aligned LLMs, it also presents an opportunity to enhance the security and safety of these models. Continued research and development in this area will be crucial to stay ahead of potential adversarial attacks and ensure the responsible and ethical use of AI technologies.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on LinkedIn. Do join our active AI community on Discord.
If you like our work, you will love our Newsletter 📰


Thanks for sharing. I read many of your blog posts, cool, your blog is very good.