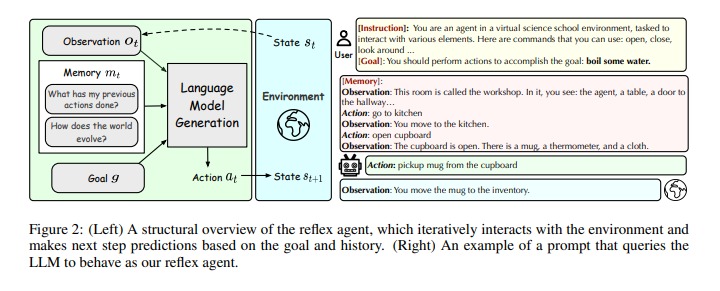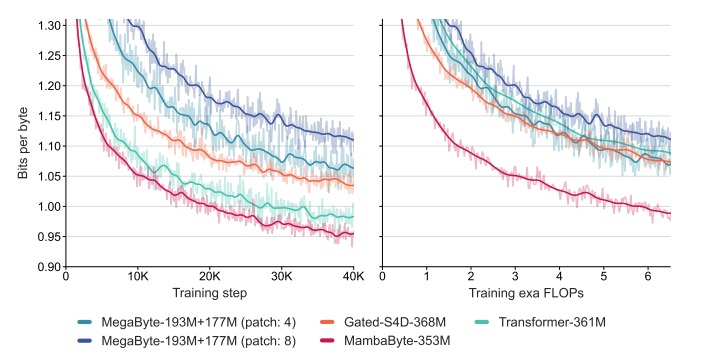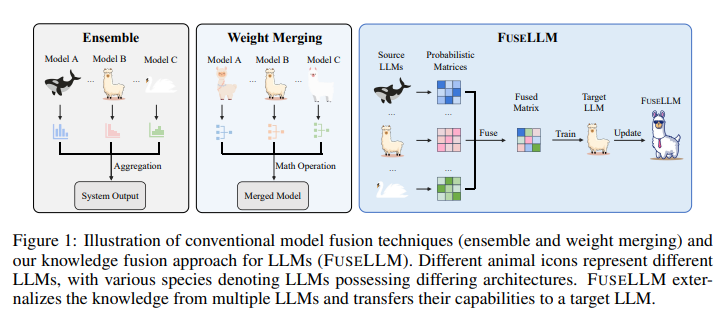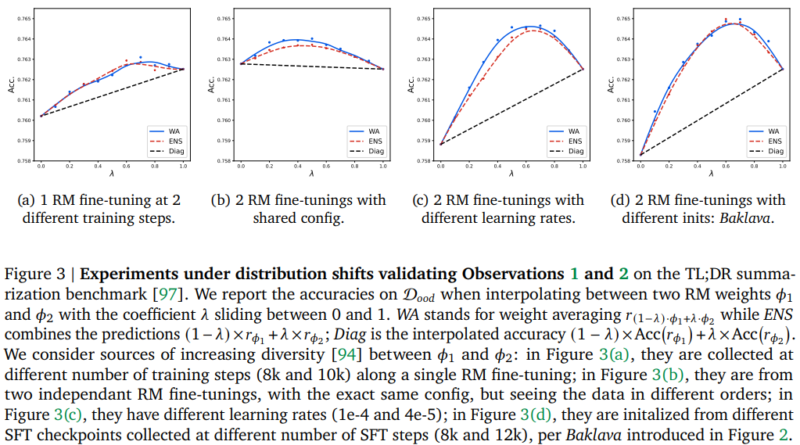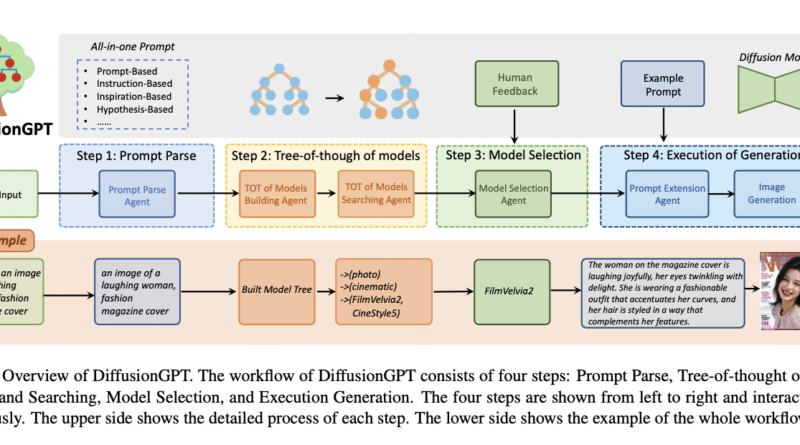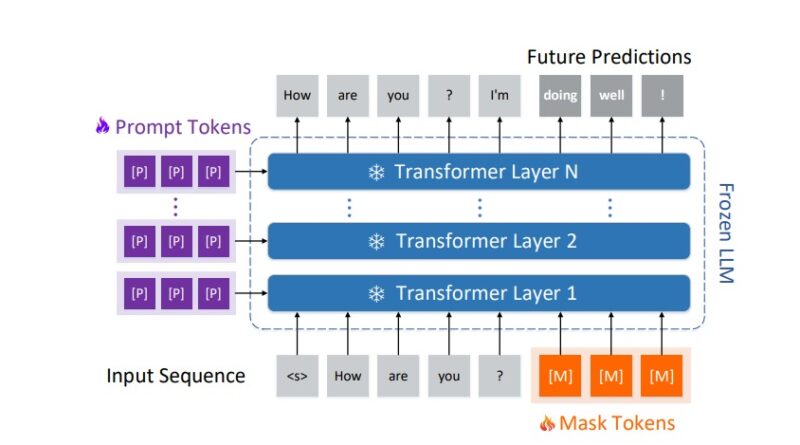
Meet BiTA: An Innovative AI Method Expediting LLMs via Streamlined Semi-Autoregressive Generation and Draft Verification
Large language models (LLMs) have revolutionized the field of natural language processing (NLP) in recent years. These models, based on
Read More